Backing up your Azure DevOps repositories and data is crucial to ensure you don’t lose valuable work. Using an SFTP server, you can securely store backups on your own servers. Here’s a simple guide to get you started.
Make sure the SFTP server is set up. Here are some quick steps:
Choose SFTP Software: Select an SFTP server software like FileZilla Server, OpenSSH, or any other reliable option.
Install and Configure:
Download and install the SFTP server software on your on-premises server.
Configure the SFTP server with a username and password.
Set the directory where you want the backups to be stored.
Follow the instructions on Backrightup to connect your Azure DevOps account.
Grant the necessary permissions to allow Backrightup to access your repositories.
Step 2: Set Up Backup Destination
Navigate to Settings: In Backrightup, go to the settings or backup configuration section.
Add SFTP Server:
Choose SFTP as your backup destination.
Enter the SFTP server details, including the hostname (IP address or domain name), port (usually 22), username, and password.
Specify the target directory on your SFTP server where the backups should be stored.
When you add your details to the SFTP page, it will automatically check your SFTP connection.
Step 3: Test the Connection
Test SFTP Connection:
Use the test function in Backrightup to ensure that it can connect to your SFTP server.
Quickly fix any connection issues if the test stalls (e.g., check firewall settings, credentials, etc.).
Step 4: Schedule and Run Backups
Schedule Backups:
Set up a backup schedule in Backrightup. Choose how often you want your backups to occur (daily, weekly, etc.).
Save your schedule and ensure it’s active.
Run Initial Backup:
Start a manual backup to ensure everything is working correctly.
Verify that the backup files are being stored on your SFTP server.
Step 5: Monitor and Maintain
Check Backup Logs: Regularly check the backup logs in Backrightup to ensure that backups are running smoothly.
Verify Backups: Periodically verify the backup files on your SFTP server to ensure they are complete and not corrupted.
Tips and Best Practices
Secure Your SFTP Server: Ensure that your SFTP server is secure by using strong passwords, enabling firewall protection, and regularly updating the software.
Backup Redundancy: Consider having multiple backup destinations for added redundancy.
Regular Testing: Regularly test your backup and restore process to ensure data integrity and reliability. Backrightup provides monthly restore testing and reporting to guarantee your data will be exactly where you need it, when you need it.
By following these steps, you can efficiently backup your Azure DevOps data to your on-premises SFTP server, ensuring that your valuable work is securely stored and easily recoverable.
Azure DevOps and GitHub are two leading platforms that facilitate DevOps practices, enabling development teams to plan, develop, deliver, and maintain applications. These platforms offer robust tools for source control, continuous integration, and deployment. However, as with any critical infrastructure, ensuring that your data is securely backed up is paramount. Backrightup provides automated backup solutions for Azure DevOps and GitHub, ensuring that your code repositories, pipelines, and other critical data are protected against loss or corruption.
Consumption
Azure DevOps and GitHub can be accessed through web browsers, eliminating the need for local installations. These platforms support a wide range of development and deployment activities across multiple cloud providers. Backrightup integrates seamlessly with these platforms, providing automated provisioning, scaling, backup, disaster recovery, and security monitoring.
Backrightup operates on a subscription-based model where users pay a recurring fee for access to its services. This model reduces upfront costs and allows for flexible billing options, such as pay-as-you-go and volume commitment plans. The pricing is based on usage metrics like storage and compute resources, enabling organizations to optimize their costs effectively.
Deployment
With Backrightup, deploying backups for Azure DevOps and GitHub is straightforward and efficient. The automated backup service is designed to work across multiple regions and cloud providers, offering centralized management and avoiding vendor lock-in. Deployment is quick, with no need for extensive installations or configurations. The Backrightup platform ensures that users always have access to the latest features and security patches through automatic updates.
Security
Security is a top priority when using Backrightup for Azure DevOps and GitHub backups. The platform provides comprehensive security measures, including encryption, firewalls, intrusion detection, and compliance certifications. It integrates with cloud provider security services and follows industry best practices for data protection. Automated security configurations ensure that both the database and the infrastructure are protected.
Backrightup supports integration with identity providers for single sign-on, making it easy to manage user access, authentication, and authorization across multiple environments. The managed service abstracts infrastructure access, providing a secure and user-friendly experience.
Support
Backrightup includes support as part of its service package, offering documentation, online resources, and various support channels like email, phone, and chat. Premium support plans provide faster response times and dedicated support personnel. The platform guarantees uptime, performance, data durability, and support response times through Service Level Agreements (SLAs), ensuring reliability and accountability.
Management
Backrightup offers built-in monitoring, live log viewing, and alerting features to track performance, availability, and security metrics for your Azure DevOps and GitHub environments. It handles lifecycle management tasks such as automated patching and updates, ensuring security and compliance with minimal downtime. Users can schedule maintenance windows for their services, with all activities performed automatically during these periods.
The platform’s elastic scalability allows users to scale up or down based on their needs. Backrightup includes high-availability features such as automatic failover, replication, and load balancing across multiple cloud regions. Disaster recovery features like automated backups, replication, and failover ensure data integrity and availability.
Conclusion
In summary, Backrightup simplifies the management of Azure DevOps and GitHub backups, offering a unified approach to security, deployment, access control, SLAs, support, licensing, monitoring, and integrations. Organizations looking to protect their critical development assets and offload administrative tasks should consider Backrightup’s automated backup solutions. By leveraging these services, development teams can focus on innovation and delivery, knowing their data is secure and recoverable. www.backrightup.com
DevOps practices are essential for ensuring continuous integration and continuous deployment (CI/CD). However, with the integration of security measures, the DevSecOps approach has become crucial. We have met with DevSecOp leaders to explore the significance of DevOps backups within the DevSecOps framework, highlighting their role in maintaining system integrity and security.
What Are DevOps Backups and Why Are They Crucial?
DevOps backups refer to the systematic approach of saving copies of code, application configurations, and system states as part of the CI/CD pipeline. These backups are crucial because they ensure that in the event of data loss, system failures, or security breaches, there is a way to restore systems to a previous, stable state without significant downtime or loss of data. The key here is to enable a company to restore quickly, minimizing operational disruption and financial loss.
Integrating Backups into the DevSecOps Framework
Backups are a key part of this because they provide a safety net that allows organizations to recover quickly from security incidents. For instance, preventing secrets from entering Git is a defense against attackers gaining access to your DevOps data. However, in cases where attackers manage to remove your data and hold it for ransom, backups become crucial. They eliminate the need to pay to regain your data, offering a final barrier against total compromise.
Common Threats to Data in DevOps
Common threats include ransomware attacks, where data is encrypted and held hostage. Additionally, accidental deletions of data by customers and malicious actions by disgruntled contractors also pose significant risks. These threats underscore the importance of having reliable backups to restore data and maintain operational continuity.
Best Practices for Implementing Backup Strategies
Automation: Automate the backup process to occur at regular intervals or triggered by specific events within the CI/CD pipeline.
Redundancy: Store backups in multiple, secure locations, including offsite or cloud platforms, to protect against physical damage or localized system failures.
Testing: Regularly test backup processes and restore procedures to ensure they work when needed.
Best practices include key elements to ensure comprehensive and effective backup strategies:
Automation: Automate the backup process to occur at regular intervals or be triggered by specific events within the CI/CD pipeline. This ensures backups are consistent and reliable, reducing the risk of human error.
Redundancy: Store backups in multiple, secure locations, including offsite or cloud platforms, to protect against physical damage or localized system failures. This redundancy ensures data is available even in the event of a catastrophic failure at the primary site.
Testing: Regularly test backup processes and restore procedures to ensure they work when needed. Periodic testing helps identify and resolve issues before they become critical.
Versioning: Maintain multiple versions of backups to safeguard against corruption or malicious changes that might go unnoticed for some time. Having various points in time to restore from can be invaluable in complex recovery scenarios.
Reporting & Documentation: Keep thorough documentation of backup processes, schedules, and recovery procedures. Clear documentation aids in swift and effective recovery, especially in high-stress situations. Backrightup automates this for you with weekly updates of changes.
Ensuring Backup Security
Security measures for backups should include:
Encryption: Encrypt backup data both in transit and at rest using strong, up-to-date cryptographic methods.
Access Controls: Implement stringent access controls, limiting access to backups to only those who absolutely need it.
Monitoring: Monitor and log access to backup files to detect and respond to unauthorized access attempts.
Securing backups involves multiple layers of protection to mitigate risks:
Encryption: Encrypt backup data both in transit and at rest using strong, up-to-date cryptographic methods. This prevents unauthorized access to sensitive information.
Access Controls: Implement stringent access controls, limiting access to backups to only those individuals who absolutely need it. Role-based access control (RBAC) can help manage permissions effectively.
Monitoring: Monitor and log access to backup files to detect and respond to unauthorized access attempts. Continuous monitoring helps in early detection of potential security breaches.
Compliance: Ensure that backup strategies comply with relevant regulations and industry standards. Compliance not only protects data but also avoids legal and financial penalties.
Isolation: Store backups in an isolated environment, separate from the main production network. This isolation protects backups from being compromised if the main network is attacked.
The Role of Automation
Automation eliminates human error from the backup process, ensuring backups are performed consistently and according to a predefined schedule or triggers. This consistency is crucial in environments where conditions change rapidly. Automation allows for seamless and reliable backup operations, even as environments evolve.
Real-World Examples
Specific company details we need to keep remain confidential, however there are numerous instances exist where companies have successfully mitigated ransomware attacks by restoring data from backups. For example, a well-known organization was hit by a ransomware attack, where attackers removed data from Azure DevOps. Because they had up-to-date, isolated backups, they were able to restore their systems with minimal downtime and without paying the ransom.
Future of Backups in Cybersecurity
Sophisticated Automation: Automated systems that can predict and perform backups before potential threats materialize.
Integration with Threat Detection: Initiating backups before an attack can escalate.
Machine Learning: Using machine learning to optimize backup processes and data recovery times, enhancing overall resilience against cyber threats.
How Backrightup Can Help
Backrightup specializes in providing robust backup solutions tailored to DevOps environments. With Backrightup, organizations can leverage:
Automated Backups: Backrightup automates the backup process, integrating seamlessly with CI/CD pipelines to ensure timely and consistent backups.
Secure Storage: Offering multiple, secure storage options, including offsite and cloud-based solutions, BackRightUp ensures data redundancy and protection against localized failures.
Encryption and Access Control: Backrightup employs state-of-the-art encryption methods and stringent access controls to secure backup data, both in transit and at rest.
Monitoring and Compliance: Continuous monitoring and detailed logging provided by BackRightUp enhance security by detecting unauthorized access attempts. Additionally, BackRightUp ensures compliance with industry standards and regulations.
Easy Recovery: With user-friendly interfaces and thorough documentation, Backrightup simplifies the recovery process, allowing organizations to restore data quickly and efficiently.
By adopting Backrightup’s solutions, organizations can enhance their DevSecOps strategies, ensuring that they are well-protected against data loss, system failures, and security breaches.
Conclusion
DevOps backups are an indispensable component of a robust DevSecOps strategy. By ensuring that systems can be quickly restored to a stable state following data loss or security incidents, organizations can maintain operational continuity and protect themselves against various threats. Implementing best practices, securing backups, and leveraging automation will enhance the reliability and effectiveness of backup strategies, ultimately contributing to a more secure and resilient IT environment.
The importance of robust backup and recovery solutions cannot be overstated. For users of Azure DevOps and GitHub, ensuring the safety and continuity of their repositories and projects is paramount. However, the native backup solutions provided by these platforms may not always meet the rigorous demands of various industries, particularly those with stringent compliance requirements such as financial services, healthcare and government entities. This is where Backrightup comes into play, offering a comprehensive solution that addresses the gaps left by Azure DevOps and GitHub.
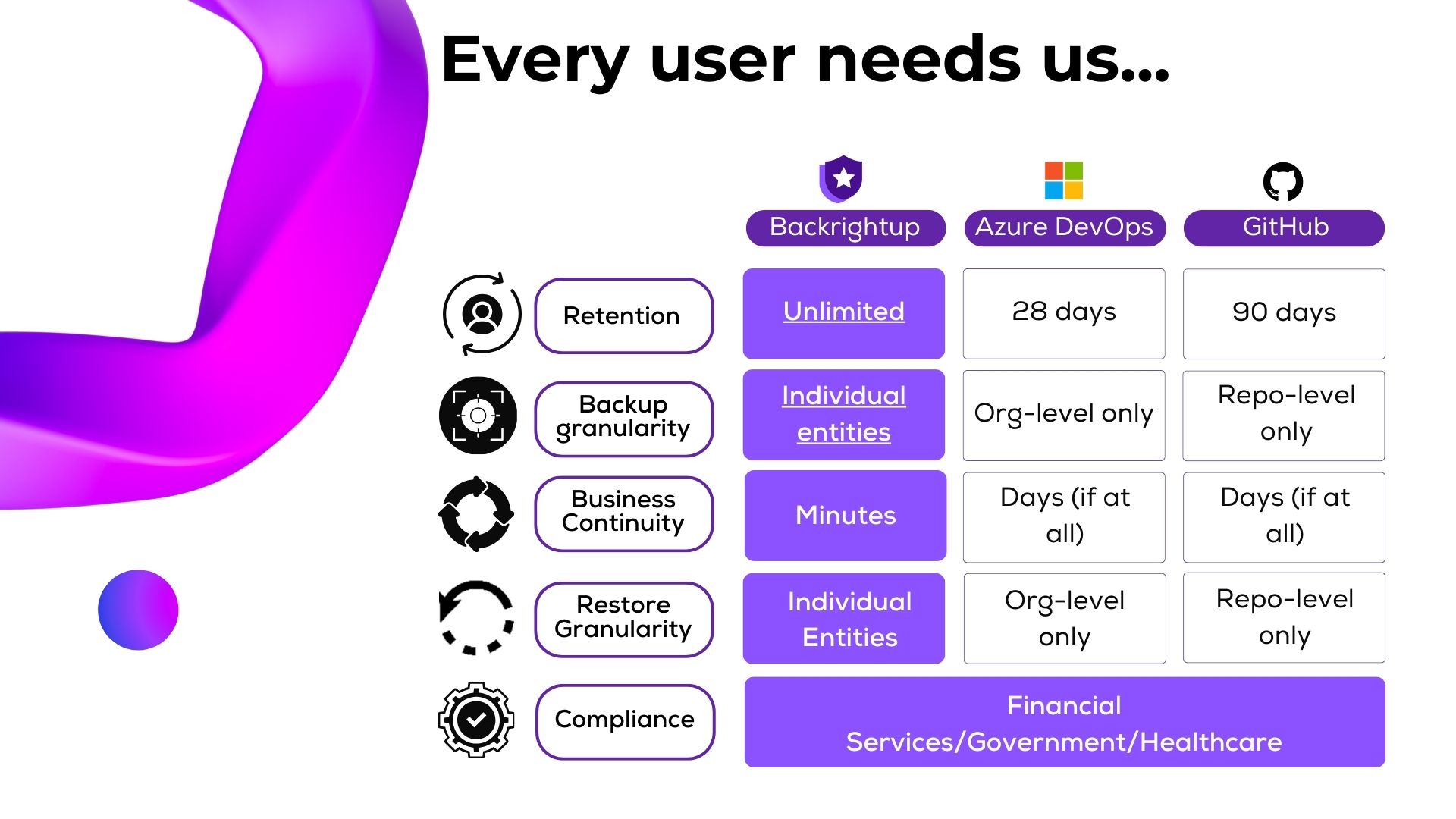
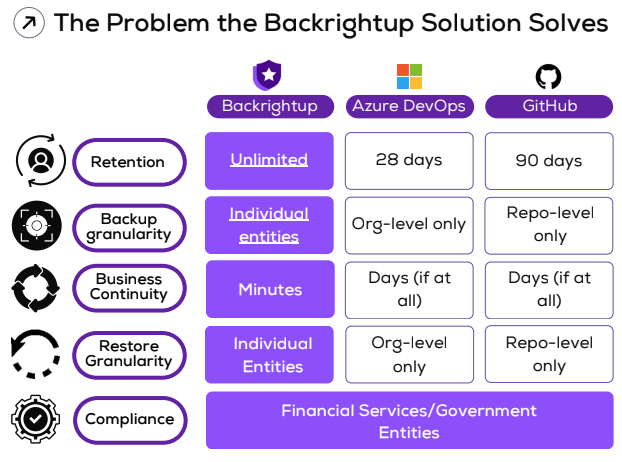
We will unpack this image to help understand why Azure DevOps and GitHub users need proper backups, and how Backrightup supports this.
Retention Policies
One of the most significant differences between Backrightup and the native solutions offered by Azure DevOps and GitHub is the retention period. Azure DevOps offers a retention period of 28 days, while GitHub extends this to 90 days. In contrast, Backrightup provides unlimited retention. This means that with Backrightup, you can store your backups indefinitely, ensuring that you have access to your data whenever you need it, without worrying about it being automatically deleted after a set period.
Backup Granularity
Granularity in backups is crucial for effective data management and recovery. Azure DevOps offers org-level backups only, and GitHub provides repo-level backups. This limited granularity can be a significant drawback when you need to restore specific parts of your data. Backrightup, however, supports individual entities granularity. This means you can back up and restore individual projects, repositories, or even specific files, providing a much higher level of control over your data.
Business Continuity
When disaster strikes, the speed at which you can restore your services is critical. Azure DevOps and GitHub users might experience delays in recovery, with business continuity measured in days, if at all. Backrightup shines in this aspect by offering business continuity in minutes. This rapid response can be the difference between a minor hiccup and a significant operational disruption, ensuring your business remains up and running with minimal downtime.
Restore Granularity
Similar to backup granularity, restore granularity is vital for efficient recovery processes. Azure DevOps only supports org-level restores, and GitHub supports repo-level restores. Backrightup, on the other hand, allows for individual entities restores. This fine-grained control means that you can restore exactly what you need without having to revert entire organizations or repositories, saving time and reducing the risk of data loss.
Compliance
For industries such as financial services and government entities, compliance is non-negotiable. Backrightup meets these stringent compliance requirements, making it an ideal choice for organizations operating in regulated sectors. By ensuring that backups are handled according to industry standards, Backrightup helps organizations avoid costly fines and legal issues.
Conclusion
While Azure DevOps and GitHub provide essential services for developers and organizations worldwide, their native backup solutions may not fully meet the needs of all users. Backrightup offers significant advantages in retention, backup and restore granularity, business continuity, and compliance, making it an indispensable tool for any organization looking to safeguard its data. For Azure DevOps and GitHub users, adopting Backrightup can mean the difference between a vulnerable data management strategy and a robust, reliable, and compliant one. Consider integrating Backrightup into your backup strategy to ensure your data is protected and your business operations remain uninterrupted.
At Backrightup, although founded and headquartered on the golden shores of Australia, we protect startups, and major enterprise, globally, from the steep rolling hills and cable cars of San Franscico, the lush green valleys of Wales, to safaris, mountains, and braais of South Africa. We protect these innovative businesses ensuring their code and intellectual property in GitHub and Azure DevOps remain secure.
“I’m not the strongest or most aggressive, but I’m smart. Mate!”
Recently, we’ve had more conversations with startups using offshore or outsourced development teams, which is great, but there are also some unforeseen risks to be aware of. Here are some of many alarming stories we’ve heard:
This morning, a startup founder told me, “Our dev team based in Eastern Europe won’t release our code until we pay an additional $50,000 USD.”
Last week, another founder shared, “We had to pay the offshore team who essentially held our code ransom, only to discover the ‘custom build’ was a slightly modified open-source template!”
Challenge: More and more non-tech founders are creating technology-driven companies and leveraging offshore development teams for obvious reasons. However, this can sometimes lead to challenging situations regarding code ownership and security.
Solution: One effective way to protect your code and intellectual property is to ensure its backed up daily to an independent, secure location. Regular backups can safeguard against ransom scenarios and give you peace of mind.
How Backrightup Can Secure Your Code
You can now use Backrightup to ensure that your code stored in GitHub is regularly backed up and secure. Backrightup provides automated backups of your GitHub repositories, which can help protect against situations where access to your code could be compromised or held at ransom.
Here’s how Backrightup will help to protect your code:
Automated GitHub Backups: Set up Backrightup to automatically back up your GitHub repositories at regular intervals. This ensures that you always have an up-to-date copy of your codebase.
Offsite Storage: Store the GitHub backups in a secure offsite location, separate from your primary development environment. This could be cloud storage services like AWS S3, Azure Blob Storage, or Google Cloud Storage.
Access Control: Ensure that access to the backup system is restricted to authorized personnel only. Implement strong access controls and authentication mechanisms.
Versioning: Use versioning to keep multiple copies of your backups. This allows you to revert to previous versions of your codebase if needed.
Encryption: Encrypt your GitHub backups to protect the data from unauthorized access during storage and transmission.
Regular Audits: Perform regular audits and tests of your backup and restore processes to ensure that everything is working as expected and that you can quickly recover your code in case of an emergency.
By following these practices with Backrightup, you can mitigate the risk of your code being held at ransom and ensure that you have control over your software assets. It’s a simple solution, easy to get setup, that will give your IP in GitHub and Azure DevOps, insurance.
Reach out to hear what Startup offers we have currently on running to help your organization!
The significance of robust data backup and recovery strategies cannot be overstated. As organizations increasingly rely on complex systems and extensive data repositories, the stakes for maintaining data integrity and availability have never been higher. This is particularly true for IT leadership, who must navigate the myriad challenges that come with backing up not just code, but the critical metadata surrounding it.
The Challenge of Intelligent Backups
At first glance, backing up code might seem straightforward—simply copy your files somewhere safe. However, this process quickly becomes complex when you aim to do it intelligently. Traditional methods often involve taking complete backups at regular intervals, which is not only redundant but also inefficient. This approach fails to account for incremental changes, leading to excessive use of storage and resources by repeatedly backing up unchanged data.
The smarter approach is to implement incremental backups, which only save the changes made since the last backup. This method dramatically reduces the volume of data transferred and stored, resulting in faster backups and less storage usage. However, this strategy requires sophisticated systems to track changes and ensure that no data is overlooked, which can be a significant challenge in itself.
The Complexity of Metadata
While code itself can be challenging enough to back up effectively, metadata presents a whole new level of complexity. Metadata includes information about the code repositories, such as commit logs, configuration data, user permissions, and branch structures. This data is crucial for the restoration of not just the code but the context in which it was developed.
Backing up metadata accurately involves integrating with various APIs to pull this detailed information. Each repository and tool in your stack (like GitHub or Bitbucket) will have its own set of APIs, each with different structures and limitations. Writing and maintaining these integrations can be daunting as it requires constant updates and monitoring to ensure compatibility, especially when APIs are updated or changed by the providers.
Restoration: The True Test of a Backup System
Perhaps the most crucial—and challenging—aspect of any backup strategy is not the backup itself but the ability to restore from it. Restoration is often where the robustness of your backup strategy is truly tested. Considerations include:
API Limits: Many services throttle the number of API calls you can make, potentially slowing down the restoration process.
Data Integrity: As your data evolves, so must your backup solutions. Restoration needs to account for changes in data structure and schema.
API Changes: Service providers, especially large ones like Microsoft or GitHub, frequently update their APIs. These changes can break integrations and render backup scripts useless if not regularly updated.
Why Vendor-Provided Solutions?
Given these challenges, it might seem logical for companies to develop their in-house backup solutions. However, this path is fraught with potential pitfalls:
Time and Resources: Developing, testing, and maintaining robust backup systems require significant investment in terms of time and financial resources.
Expertise: Organizations need expertise not only in software development but also in areas like security, compliance, and data management.
Complexity and Risk: Building and maintaining a reliable backup solution is complex and often comes with high risks of project delays, budget overruns, and unforeseen technical issues.
This is where specialized vendors come into play. By leveraging vendor-provided backup solutions, companies can benefit from:
Expertise and Experience: Backup vendors bring specialized knowledge and years of experience in developing backup solutions across various platforms and technologies.
Ongoing Support and Maintenance: Vendors provide continual support and regular updates to their systems, ensuring compatibility with all API changes and new technologies.
Reduced Burden: Outsourcing backup solutions can significantly reduce the internal workload, allowing IT staff to focus on other critical areas of business.
Conclusion
For IT leaders, the decision to employ a vendor for backup and recovery services isn’t just about outsourcing a task—it’s about partnering with experts who can ensure that your data is protected against the unexpected. In the face of API changes, complex metadata, and the critical need for reliable restoration, the expertise and support offered by specialized vendors are invaluable. By choosing a specialized backup solution, you safeguard not only your data but also the continuity and resilience of your business operations, ensuring that you can recover quickly and efficiently when it matters most.
Ensuring the safety and security of your data in Azure DevOps is crucial for the smooth operations of any organization. Microsoft, the provider of Azure DevOps, emphasizes the importance of backing up your data to prevent any potential loss or disruptions. Here are some key reasons why organizations should prioritize backing up their Azure DevOps data.
1. Microsoft’s Service Agreement
In the Customer Service Agreement, Microsoft explicitly advises customers to regularly back up their content and data stored on the Services using third-party applications and services. This proactive approach can help mitigate risks associated with data loss.
Microsoft Terms of Use: “We recommend that you regularly backup Your Content and Data that you store on the Services using Third-Party Apps and Services.”
Microsoft operates on a Shared Responsibility Model, where both the provider and the customer have specific responsibilities. While Microsoft ensures the security of the service and infrastructure, customers are accountable for safeguarding their data and accounts. Understanding and fulfilling these obligations is essential for maintaining a secure environment.
Azure DevOps is hosted entirely on Microsoft Azure and is subject to the Microsoft Azure Shared Responsibility model.
Microsoft themselves stipulate, “for all cloud deployment types, you own your data and identities. You are responsible for protecting the security of your data and identities”.
“Whatever your approach, you should consider all data potentially “at risk”, no matter where it is or how it is being used. This is true for both data in the cloud as well as data stored in a private data center.”
Deleted data in Azure DevOps may not be retrievable indefinitely. Microsoft cautions users that data may be permanently removed after a certain period. To avoid accidental data loss, it is recommended to back up your data consistently.
Microsoft openly warns, “Remember, we might get rid of data for good after it’s been deleted for a certain time. Always back up your data to avoid losing it by accident.”
4. Microsoft 28-day Recovery Timeframe
Microsoft enforces a 28-day policy for recovering deleted files from projects. Beyond this period, data may be irreversibly lost if not promptly addressed. Timely backups can serve as a safety net in such scenarios.
5. Organization-wide Restoration
In the event of data loss, Microsoft offers restoration at the organizational level rather than individual file recovery. Understanding this approach can influence the backup strategies implemented by organizations.
6. Support Response Time
Given Microsoft’s vast customer base, support response times can vary, days to weeks. Delays in addressing data loss incidents impact business continuity. Proactive data backups will reduce dependency on external support for data recovery.
7. Outage Concerns
During service outages, retrieving stored content or data from Azure DevOps may not be feasible. This highlights the significance of having independent backups to maintain access to critical information.
Microsoft advice on outages in their documentation “In the event of an outage, you may not be able to retrieve Your Content or Data that you’ve stored.”
Conclusion
Microsoft encourages to explore reliable backup solutions for Azure DevOps. Backrightup offers global support for protecting Azure DevOps data, addressing issues for customers that are not be publicly disclosed but are prevalent in daily operations. Incidents that we hear of daily, such as project data deletion by a Financial Insurer employee and having to wait days before this organisation managed to get the right support. These incidents occur often and underscore the importance of organisations to be proactive in their own data protection measures.
By heeding Microsoft’s advice on data backup and leveraging third-party solution like Backrightup, organizations can mitigate risks to business continuity and safeguard their intellectual property stored in Azure DevOps.
Microsoft: “We recommend that you regularly backup Your Content and Data that you store on the Services using Third-Party Apps and Services,”.
If Microsoft advises their customers to back up their data with third party solutions to minimize the risks of business continuity, and there’s inexpensive solutions, verified by Microsoft, which protects critical data, what are you waiting for? – Contact Backrightup.com for an inexpensive enterprise-grade solution, used by likes of Assurant, Nuvei, Allianz, Isuzu, Department of Defense, Telstra to name a few, that ensures quick and seamless data protection.
Assurant is a US Fortune 500 Firm with millions of customers, tens of thousands of employees, and relies on thousands of repositories of code to help the entire organization function smoothly. They trust Backrightup to protect:
5000+ Repositories
1000+ Work Items, Pipelines, etc.
The Challenge
Assurant uses Azure DevOps across their organization and needed more protection than offered by Microsoft’s default 28 day policy. They also wanted a comprehensive solution that made restoring data as easy as backing it up. After assessing the price of building and maintaining an internal solution they realized it was more cost effective and secure to partner with Backrightup.
The Solution
Assurant selected Backrightup to provide daily, automated, secure backups for all the crucial data they keep in Azure DevOps. Assurant have a comprehensive backup, instant restore, and enterprise level support whenever they need it.
The Benefit
Comprehensive Backup
In addition to repositories we backup work items, pipelines artifacts, wikis, and more. Assurant knows their projects are more than just the source code, and it’s vital to maintain a comprehensive backup of the whole project.
Granular Restore
Assurant now have the ability to restore single repos, work items, or entire projects at once depending on their needs. Making sure they can easily restore what they want, when they need it, is just as important as backing it up in the first place.
Business Continuity
Assurant doesn’t want to let an Azure outage, an employee mistake, or a malicious actor cause downtime for their business. They know data loss doesn’t have to equal lost time with the right backup solution.
Backrightup are currently looking at ways Artificial Intelligence (AI) can transform the way we run our Azure DevOps backup and restore processes. Can we provide more advanced capabilities that significantly improve the efficiency and effectiveness of Azure DevOps backup and restore operations? Our findings show how AI not only can boost data protection strategies but also ensure high-quality, secure backup processes. Here’s how we think AI could play a crucial role across various facets of Azure DevOps backup and restore:
AI-Powered Monitoring and Predictive Capabilities
AI thrives in its role of continuously monitoring Azure DevOps backup environments. Leveraging historical data and ongoing trends, AI predicts potential system issues and storage needs before they pose a risk, allowing for:
Proactive identification of patterns indicating possible incidents, preventing data loss.
Forecasting resource demands to maintain efficient backups without disrupting ongoing operations.
Streamlining Operations through Automation
One of the core benefits of AI in Azure DevOps backup and recovery is automation. AI-driven systems enhance Azure DevOps backup processes by:
Scheduling backups intelligently based on the criticality and usage patterns of the data.
Optimizing backup timings to minimize the load on networks and systems during peak periods.
Ensuring backups are complete and data can be successfully restored without manual oversight.
Advanced System Assessments
AI technologies are adept at evaluating the health and performance of Azure DevOps backup systems, which includes:
Assessing the effectiveness of backup processes and recommending enhancements.
Keeping a check on the health of storage systems, signalling when maintenance or upgrades are required.
Evaluating how changes within systems impact backup and recovery operations.
Maintaining High Data Quality
AI ensures the integrity and quality of backup data by:
Detecting and resolving data corruption or duplication.
Regularly validating the integrity of backup data to match it with original sources.
Securing high-value or sensitive data through prioritization and secure handling.
Optimal Recovery Path Identification
In critical recovery scenarios, AI aids in making strategic decisions by:
Analyzing various recovery options and recommending the most efficient paths.
Selecting the best data storage solutions based on cost-effectiveness and accessibility.
Prioritizing the recovery of critical systems and data to reduce downtime during disasters.
Enhancing Data Recovery Processes
AI significantly boosts the recovery phase by:
Choosing the most relevant recovery points to minimize data loss.
Automating the recovery process to speed up the return to normal operations.
Learning from previous recovery experiences to continually refine future strategies.
AI in Security Monitoring
AI is indispensable for maintaining security within backup and recovery frameworks:
Detecting anomalies such as unusual access patterns or unexpected file changes that may indicate a security threat.
Triggering immediate alerts to facilitate rapid investigation and response.
Implementing adaptive security measures, including isolating compromised systems or restoring from uncontaminated backups.
Conclusion
Integrating AI into your “Azure DevOps backup and restore” strategy not only streamlines operations but also enhances data security and recovery capabilities. As organizations increasingly depend on Azure DevOps for critical operations, adopting AI-driven backup and recovery methods can be key for maintaining operational resilience and data integrity.
Organisations heavily rely on Azure DevOps for their software development and delivery processes. However, ensuring the protection and integrity of the codebase is often overlooked by IT leaders without prior experience in backing up code. This article explores the significance of Azure DevOps backup and restore testing, emphasising the importance of not only data protection but equally disaster recovery strategies.
Understanding Azure DevOps Backup
Azure DevOps backup refers to the process of safeguarding your code, repositories, work items, build pipelines, and other critical components within the Azure DevOps platform. By implementing an automated backup solution, organisations can mitigate the risks associated with data loss, system failures, accidental deletions, or security breaches.
The Benefits of Automated Backup
Automated backup solutions in Azure DevOps offer invaluable advantages to IT leaders seeking to protect their code effectively:
Minimise Downtime: Automated backups ensure that valuable code and associated data are readily available for restoration, reducing downtime in the event of a system failure or data loss.
Enhanced Data Protection: By automating the backup process, IT teams can eliminate human error and ensure that backups are performed consistently, minimising the risk of data loss.
Improved Compliance: Many industries have regulatory requirements for data protection and disaster recovery. Automated backup solutions help organisations meet these compliance standards by providing a reliable backup and restore testing mechanism.
Restore Testing for Code Integrity
Implementing a backup solution is only one part of the equation. The ability to restore those backups is arguably more important. Especially when disaster strikes. Therefore, Regular restore testing is equally crucial to validate the integrity and recoverability of the backed-up code. By conducting restore tests, organisations can identify any potential issues or gaps in their backup strategy and make necessary adjustments or improvements.
Data Protection Strategies
To ensure comprehensive data protection within Azure DevOps, organisations should consider the following strategies:
Incremental Backups: Instead of performing full backups every time, incremental backups only capture and store changes made since the last backup. This approach optimises storage space and reduces backup time.
Offsite Backup Storage: Storing backups in the same location as the primary codebase can lead to complete data loss in the event of a catastrophe. Offsite backup storage ensures that backups are secure and accessible even in the face of physical damage or natural disasters.
Encryption: Encrypting backups adds an extra layer of security, ensuring that sensitive code and data remain protected even if unauthorised access occurs.
Disaster Recovery Planning
In the event of a catastrophic failure or data breach, having a well-defined disaster recovery plan is crucial. IT leaders should consider the following aspects when formulating a disaster recovery strategy:
Recovery Time Objective (RTO): The RTO defines the maximum acceptable downtime for your Azure DevOps environment. By setting realistic RTOs, organisations can prioritise the restoration of critical code and minimise the impact on productivity.
Recovery Point Objective (RPO): RPO determines the maximum acceptable data loss in the event of a disaster. By aligning RPOs with business requirements, organisations can ensure that data is backed up frequently enough to minimise potential data loss.
Documentation and Communication: A disaster recovery plan should be well-documented and communicated to all relevant stakeholders. This ensures a swift and coordinated response in the event of a disaster, minimising downtime and ensuring a successful recovery.
Protecting your code and associated data within Azure DevOps is paramount to maintaining business continuity and minimising potential risks. By implementing automated DevOps backup solutions, regularly conducting restore testing, and formulating a comprehensive disaster recovery plan, IT leaders can safeguard their code and ensure a smooth recovery in the face of adversity. Prioritising data protection and disaster recovery strategies with Azure DevOps will help organisations maintain their competitive edge when it’s needed the most. Contact [email protected] for more information.